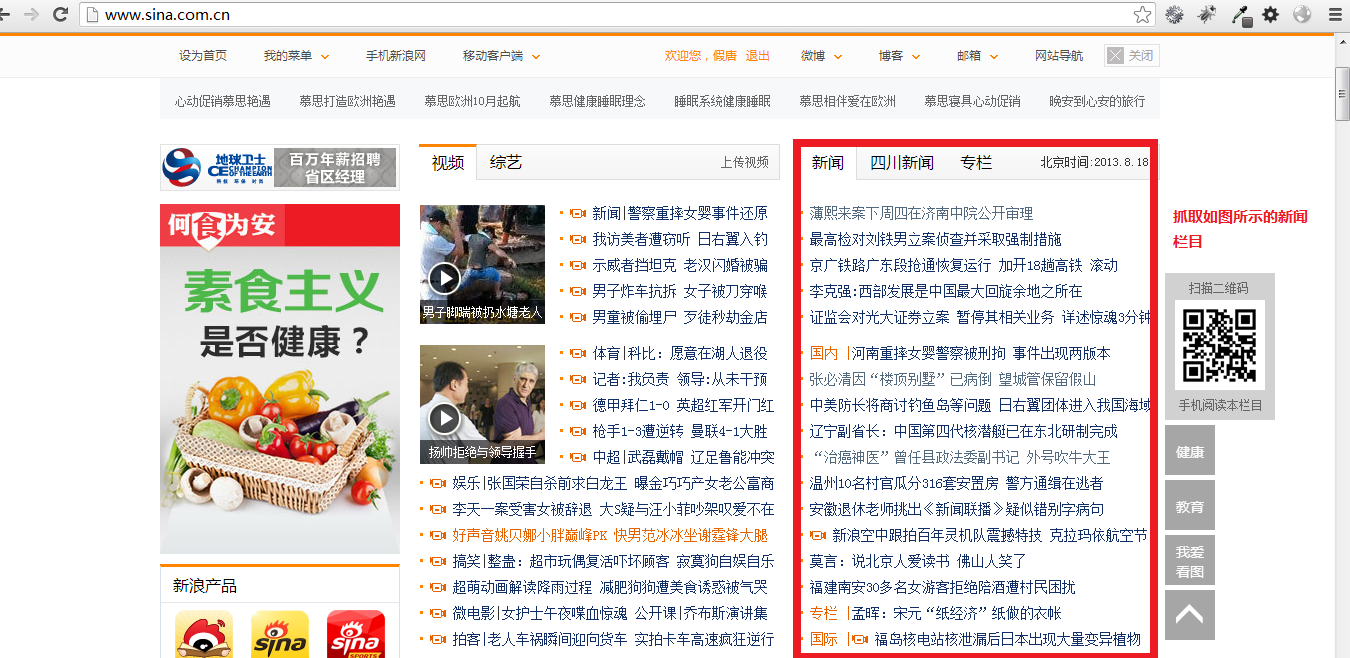
抓取新浪网的新闻栏目,如图所示:

使用 谷歌浏览器的查看源代码: 通过分析得知,我们所要找的内容在以下两个标签之间:
复制代码 代码如下:
<!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' -->
内容。。。。
<!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' -->
如图所示:

内容。。。。

使用VS建立一个如图所示的网站:

我们下载网络数据主要通过 WebClient 类来实现。
使用下面源代码获取我们选择的内容:
复制代码 代码如下:
protected void Enter_Click(object sender, EventArgs e)
{
WebClient we = new WebClient(); //主要使用WebClient类
byte[] myDataBuffer;
myDataBuffer = we.DownloadData(txtURL.Text); //该方法返回的是 字节数组,所以需要定义一个byte[]
string download = Encoding.Default.GetString(myDataBuffer); //对下载的数据进行编码
//通过查询源代码,获取某两个值之间的新闻内容
int startIndex = download.IndexOf("<!-- publish_helper name='要闻-新闻' p_id='1' t_id='850' d_id='1' -->");
int endIndex = download.IndexOf("<!-- publish_helper name='要闻-财经' p_id='30' t_id='98' d_id='1' -->");
string temp = download.Substring(startIndex, endIndex - startIndex + 1); //截取新闻内容
lblMessage.Text = temp;//显示所截取的新闻内容
}
效果如图:

最后: 除了把下载的数据保存为文本以外,还可以保存为 文件类型 和 流 类型。
复制代码 代码如下:
WebClient wc = new WebClient();
wc.DownloadFile(TextBox1.Text, @"F:\test.txt");
Label1.Text = "文件下载完成";
复制代码 代码如下:
WebClient wc = new WebClient();
Stream s = wc.OpenRead(TextBox1.Text);
StreamReader sr = new StreamReader(s);
Label1.Text = sr.ReadToEnd();
|